sometimes we have to match the data by name because there might be issues on the matching id. But when match by name, we might have some issues like: strict word matching will not match "apple iphone" and "iphone apple" as the same, but theyshould be treated as the same in fact. This is an example how to do fuzzy match to solve this kind of question.
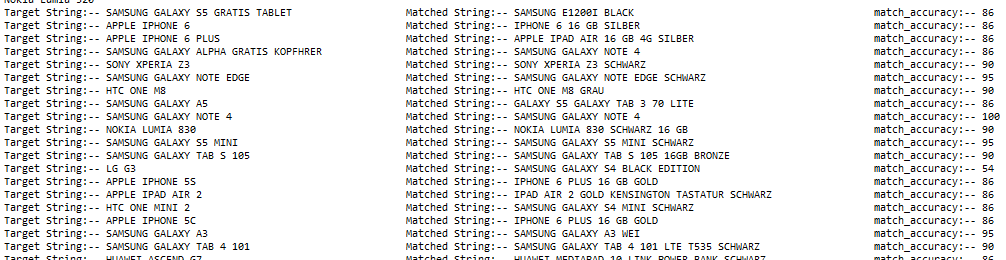
An example of the output result:
import re
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
'''
test sample data is from
http://bigdata-doctor.com/wp-content/uploads/2015/02/source1.csv
http://bigdata-doctor.com/wp-content/uploads/2015/02/source2.csv
'''
def readdata(datapath):
f = open(datapath, 'r')
fr = f.read().split('\n')
testdata = []
for line in fr[1:]:
if len(line) > 0:
text = line.split(';')[1].replace('"', '')
print text
testdata.append(text.decode('utf-8').upper())
return testdata
def tslt_spec(x):
# x1 = re.sub('[^a-zA-Z0-9 \n\.]', '', x) # replace special char to blank
x1 = re.sub('[^a-zA-Z0-9 \n]', '', x) # replace special char to blank
x2 = re.sub(' +', ' ', x1) # multiple blanks to one blank
x3 = x2.strip() # remove heading/tailing blanks
x4 = x3.upper() # remove the tailing numbers if there is, 'SOUTH COAST 9999837411'
return x4
ls1 = readdata(r'C:\Users\hsong01\Downloads\source1.txt')
ls2 = readdata(r'C:\Users\hsong01\Downloads\source2.txt')
ls1 = [tslt_spec(x) for x in ls1]
ls2 = [tslt_spec(x) for x in ls2]
result = {}
for i in ls2:
try:
mi = process.extract(i, ls1, limit = 1)
print 'Target String:-- ' + i.ljust(50) + 'Matched String:-- ' + mi[0][0].ljust(60) + 'match_accuracy:-- ' + str(mi[0][1])
result[i] = mi
except:
print i
len([x[0][0] for x in result.values() if x[0][0][1] > 90])