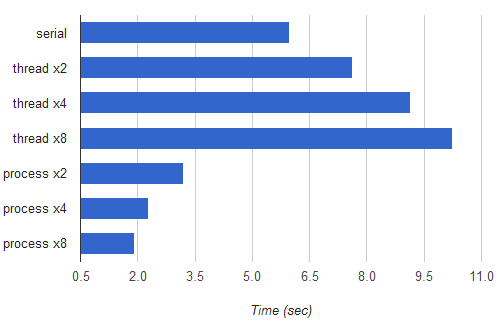
在cpu-bound的情形下,多进程会比多线程快很多,这里主要引用Python - parallelizing CPU-bound tasks with multiprocessing的结果,来比较multiprocessing.Process v.s. threading.Thread
在使用multiprocessing.Process v.s. threading.Thread进行多进程或者多线程的时候,跟使用multiprocessing.Pool是不一样的:
假如对range(1000000)产生的1000000个整数,每个整数用函数factorize_naive求质因子:
-
multiprocessing.Pool是先通过进程池批量建立多个进程(比如下例中6个p = Pool(npool)),然后6个进程同时run(p.map(factorize_naive, range(1000000))),比如先对0~5 run factorize_naive 求质因子,然后哪个进程先结束,就会对6求质因子,下一个进程结束,就会run factorize_naive(7),等等下去,后台始终有6个进程在跑。 -
multiprocessing.Process不是建立进程池,而是根据要开的进程数(6)首先把data split成6个subset(chunksize = int(math.ceil(len(nums) / float(nprocs)))),(每个subset有1000000/6个整数),然后6个进程每个进程跑一个subset(multiprocessing.Process(target=worker, args=(nums[chunksize * i:chunksize * (i + 1)], out_q)))
最后的总结:
-
multiprocessing让我们可以充分利用多核CPU的性能,在我们遇到的大部分情况下(cpu bound),multiprocessing比threading或者serialrun要快不少 -
在
multiprocessing下,使用multiprocessing.Process或者multiprocessing.Pool map差别不是很大 -
multiprocessing.Pool map会批量处理,而且返回的结果跟输入data次序相同 -
所以我会优先选择
multiprocessing.Pool map
import threading
import multiprocessing
from multiprocessing import Process, Queue, Pool
import math
import timeit
def factorize_naive(n):
""" A naive factorization method. Take integer 'n', return list of
factors.
"""
if n < 2:
return []
factors = []
p = 2
while True:
if n == 1:
return factors
r = n % p
if r == 0:
factors.append(p)
n = n / p
elif p * p >= n:
factors.append(n)
return factors
elif p > 2:
# Advance in steps of 2 over odd numbers
p += 2
else:
# If p == 2, get to 3
p += 1
assert False, "unreachable"
def serial_factorizer(nums):
return {n: factorize_naive(n) for n in nums}
def threaded_factorizer(nums, nthreads):
def worker(nums, outdict):
""" The worker function, invoked in a thread. 'nums' is a
list of numbers to factor. The results are placed in
outdict.
"""
for n in nums:
outdict[n] = factorize_naive(n)
# Each thread will get 'chunksize' nums and its own output dict
chunksize = int(math.ceil(len(nums) / float(nthreads)))
threads = []
outs = [{} for i in range(nthreads)]
for i in range(nthreads):
# Create each thread, passing it its chunk of numbers to factor
# and output dict.
t = threading.Thread(
target=worker,
args=(nums[chunksize * i:chunksize * (i + 1)],
outs[i]))
threads.append(t)
t.start()
# Wait for all threads to finish
for t in threads:
t.join()
# Merge all partial output dicts into a single dict and return it
return {k: v for out_d in outs for k, v in out_d.iteritems()}
def mp_factorizer(nums, nprocs):
def worker(nums, out_q):
""" The worker function, invoked in a process. 'nums' is a
list of numbers to factor. The results are placed in
a dictionary that's pushed to a queue.
"""
outdict = {}
for n in nums:
outdict[n] = factorize_naive(n)
out_q.put(outdict)
# Each process will get 'chunksize' nums and a queue to put his out
# dict into
out_q = Queue()
chunksize = int(math.ceil(len(nums) / float(nprocs)))
procs = []
for i in range(nprocs):
p = multiprocessing.Process(
target=worker,
args=(nums[chunksize * i:chunksize * (i + 1)],
out_q))
procs.append(p)
p.start()
# Collect all results into a single result dict. We know how many dicts
# with results to expect.
resultdict = {}
for i in range(nprocs):
resultdict.update(out_q.get())
# Wait for all worker processes to finish
for p in procs:
p.join()
return resultdict
# serial run
start = timeit.default_timer()
serial_factorizer(range(1000000))
end = timeit.default_timer()
print "Serial run time is %s" %(end - start)
# threading run
start = timeit.default_timer()
threaded_factorizer(range(1000000), nthreads = 6)
end = timeit.default_timer()
print "threading run with 6 threads, run time is %s" %(end - start)
start = timeit.default_timer()
mp_factorizer(range(1000000), 6)
end = timeit.default_timer()
print "multiprocessing run with 6 process, run time is %s" %(end - start)
start = timeit.default_timer()
mp_factorizer(range(1000000), 80)
end = timeit.default_timer()
print "multiprocessing run with 80 process, run time is %s" %(end - start)
Figure 1. compare serial v.s. threading
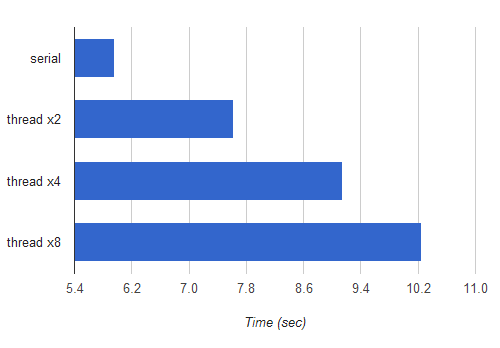
Figure 2. compare serial, threading and multiprocessing