1. GPT-1
Improving Language Understandingby Generative Pre-Training
What the problem GPT-1 solve?
Before GPT-1, NLP was usually a supervised model. For each task, there are some labeled data, and then develop a suoervised model based on these labeled data. There are several problems with this approach: First, labeled data is required. But NLP does not like CV which has a well-labeled data imagenet. Second, the models trained by these different tasks are not very general. For example, it is difficult to directly use the model trained by translation on classification.
GPT-1 puts forward some ideas: First, there are a lot of texts without labels in reality, can we use these large amount of unlabeled data? Second, is it possible to pre-train a general model that can be transfered to handle different tasks? However, leveraging the unlabeled data is challenging for 2 main reasons. First, what objective function should be used to optimize to learn the text representation that can be transferable? Second, there is no consensus on the model to transfer these learned representations to the target task.
GPT-1 used the semi-supervised approach to achieve this objective: it used a self-supervised (which is called unsupervised in the paper) pre-trained model to learn the text representation from the large amount of ublabeled data, and it used supervised models to fine-tune for each sub-task with annotated training data. I'd call it self-supervised rather than unsupervised as in ML, unsupervised model usually means the data has no labels and the task are more like clustering. Here the semi-supervised only means it does not need manual labelled data but just predict the next token (word) from the tokens (words) up to current time. More details will be introduced in the models details below.
For model structure, GPT-1 uses Transformer decoder because they think it provides a more structured memory for handling the long-term dependencies in text which results in robust transfer performance across different tasks. Compared to BERT which is also based on Transformer but it uses Transformer encoder. This means GPT-1 chooses a more difficult way than BERT because decode only uses informaiton until \(t\) to predict the next token at \(t+1\), while encoder will leverage the information before and after the masked token to predict, which is easier and performance might be better because the tokens afterwards have already been seen to make the prediciton. That is why GPT is called unidirectional (from left to right) while BERT is called Bi-directionsl (use words before and after the masked token to predict).
How does GPT-1 work (model framework)?
As introduced above, GPT-1 includes two stages. The first stage is learning a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to a discriminative task with labeled data.
1. Unsupervisded (self-supervised) pre-trained model
This task is to predict the token \(u_i\) based on the previous \(k\) tokens \((u_{i-k}, \cdots, u_{i-1})\). Given the tokens \(\mathcal{U} = \{u_1, \cdots, u_n \}\), the objective is to maximize the probability likelihood to predict the next word
where \(k\) is the size of the context window and the conditional probability \(P\) is a NN model with parameters \(\Theta\). The bigger the \(k\), the longer of the previous text that the model will see. So a bigger \(k\) usually enable the model to learn and remember better.
-
Since \(L_1(\mathcal{U}) = \sum_i \log P(u_i | u_{i-k}, \cdots, u_{i-1}; \Theta) = \log \prod_i P(u_i | u_{i-k}, \cdots, u_{i-1}; \Theta)\) and \(\prod_i P(u_i | u_{i-k}, \cdots, u_{i-1}; \Theta)\) is the joint probability of the prediciton for each word. So maximizing this joint probability is to find the \(\Theta\) so that the predicted words are the same as the input text.
-
As in the formula above, here GPT-1 choose to predict the next word based on the previous \(k\) words, while BERT will use the words before and after the target word. This makes the task in GPT a little more difficult than BERT, and thus its performance may not be as good as BERT in some tasks (which is verified in BERT paper pubished several months after GPT-1).
In the experiment, the model is a multi-layer Transfromer decoder. It applies a multi-head self-attention operation over the input tokens followed by position-wise feedforward layers. Through this transformation, the author cleverly found an objective to optimize.
where \(U = (u_{-k}, \cdots, u_{-1})\) is the context token vector, \(h_0\) is the mapping projection of \(U\), \(W_c\) is the token embedding and \(W_p\) is the position embedding.
2. Supervised fine-tuning
After the generative model is trained from the unlabelled data, GPT-1 fine tuned the pre-trained model on the subtasks by adding a task specific layer after the last layer of the pre-trained model. The parameters from the pre-trained model are adapted to the supervised subtasks by fine-tuning on the labeled data \(\mathcal{C}\), in which each instance is a sequence of input tokens \(x^1, \cdots, x^m\) along a label \(y\). The inputs are passed throught the pre-trained transformer block to get the activation \(h_l^m\), which is fed into a linear layer with softmax to predict the probability for \(y\):
The objective is to maximize the likelihood
Auxiliary training objective: rather than maximizing the likelihood funciton separately, the authors find that including language modeling as an auxiliary objective to the fine-tuning helped improving the generalizaiton of the supervised model and accelerating the convergance. So the final objective is to maximize the added two objective funciton with parameter \(\lambda\)
3. Supervised model tasks and input transformation
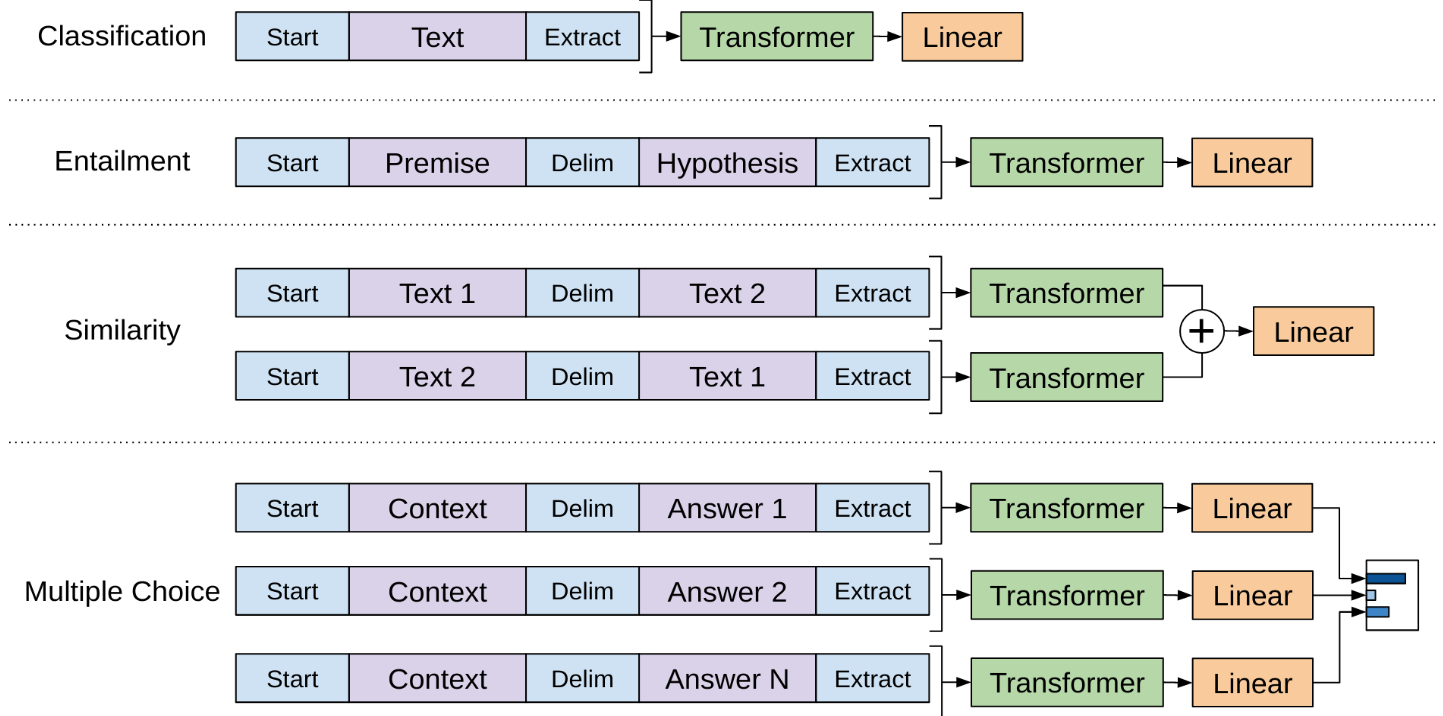
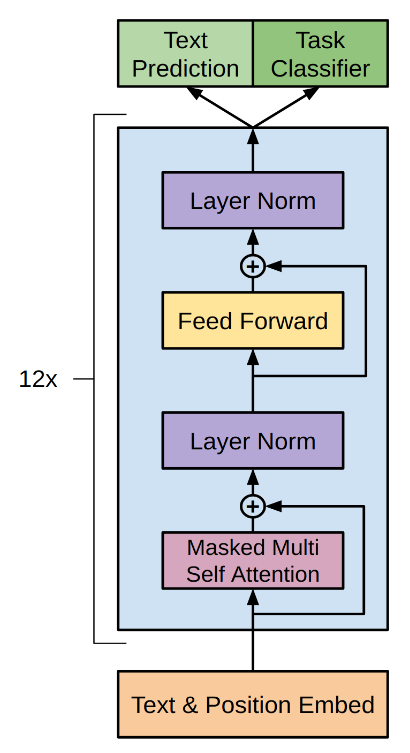
The input to the transformer decode is a sequence of tokens. For the subtasks like classification, it can be directly input to the transformer decoder. For other tasks like Entailment, Similarity and Multiple choices, the data was re-structured by adding some special tokens to indicate the Start, Delim and Extract (<BOS>, <EOS>, <PAD> etc) as is shown in the Figure 1 below. After the data being re-structured to the uniformly format, it will be split to tokens as the input to transformer decoder as is shown in Figure 2.
As the previous section described, in the fine-tuning step, the objective is the auxiliary objective which is the added two objective from the next word prediction in the pre-training model and the classification task in the fine-tuning tasks. So the output from the transformer in the fine-tuning task include two parts: text prediction and the output for classifier (See Figure 2).
Analysis and discussion
The experiment results will be ignored here. But in the Analysis section the authors provides some useful informaion why they choose transformer rather than the other languages models like LSTM.
The first observation is that the more number of layers transferred from the pre-trained model to the fine-tuning tasks, the better the performance (accuracy) is. That is, one way to improve the model performance is to increase the number of model layers (and the layer size = d_model). That is what GPT-2/3/4 will do.
The second observation is that transformer can learn to improve its language model capability with the more structured attentional memory (My understanding is that transformer has much more parameters and the attention mechanism can help to selectively remember the useful information). The author verifies this by zero-shot learning. That is, use the pre-trained model directly without fine-tuning on the subtasks. The performance of transformer is more stable and better than LSTM. That is also what GPT-2 will focus on.
2. GPT-2
Language Models are Unsupervised Multitask Learners
What the problem GPT-2 solve?
As discussed at the end of GPT-1 (and also stimulated by BERT?), the pre-trained model performance can be improved with more complex model (more layer - deeper, higher layer size - wider). It also can be used in the target tasks directly (zero-shot learning) and beat the performance of LSTM. That is GPT-2. Similar to GPT-1, GPT-2 is also the self-supervised model with transformer decoder but much more parameters. And GPT-2 mainly focus on zero-shot learning.
Why zero-shot? BERT which was introduced after GPT-1 outperformed GPT-1 in many tasks. In the last section of GPT-1, it shows the pre-trained model performance could be improved with bigger model. But if just purely increasing the parameters, the value of the GPT-2 paper may not mean too much. So GPT-2 wants to discuss from the other aspect that the model can do zero-shot: without additional training, the model can performs good in some tasks. This also shows that the gpt model has a strong generalization ability, which in fact is lacked in BERT.
How does GPT-2 work (model framework)?
Because it doesn't have fine-tuning tasks, GPT-2 does not need the special tokens like (<BOS>, <EOS> as GPT-1 did. Instead, GPT-2 uses a promot to control the input to the model. A prompt is a small piece of text provided to the model, and the model will generate the additional text based on this input. The prompt is task specific and depends on the specific input sequence and task.
In contrast, GPT-2 uses a prompt to control the input to the model. A prompt is a small piece of text that is provided to the model as an initial input, and the model generates additional text based on this input. The prompt is task-specific and depends on the specific input sequence and task. For example, to translate to French, the prompt is like "translate to french", followed by Engligh sentences, and then French sentences. So the example data is a sequence like (translate to french, english text, french text).
1. Data
Because GPT-2 has much more parameters than GPT-1, it requires more training data. To build a large and diverse dateset to collect the natual language demonstrations of tasks, the authors used the Common Crawl data. But the quality of this data set is low, so they picked the relatively higher quality subset from this data: the posts from reddit with at least 3 karma. Another dataset is WenText which is extracted from Dragnet and Newspaper content. The data is cleaned and split by Byte Pair Encoding (BPE).
2. Model
The model is almost the same as GPT-1 which is transformer decoder, with layer norm was moved to each sub-block and an additional layer norm was added after the final self-attention block.
There are different setups of the number of transformer layers and the d_model.
| Parameters | Layers | d_model |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
3. Zero-shot learning performance on the NLP tasks
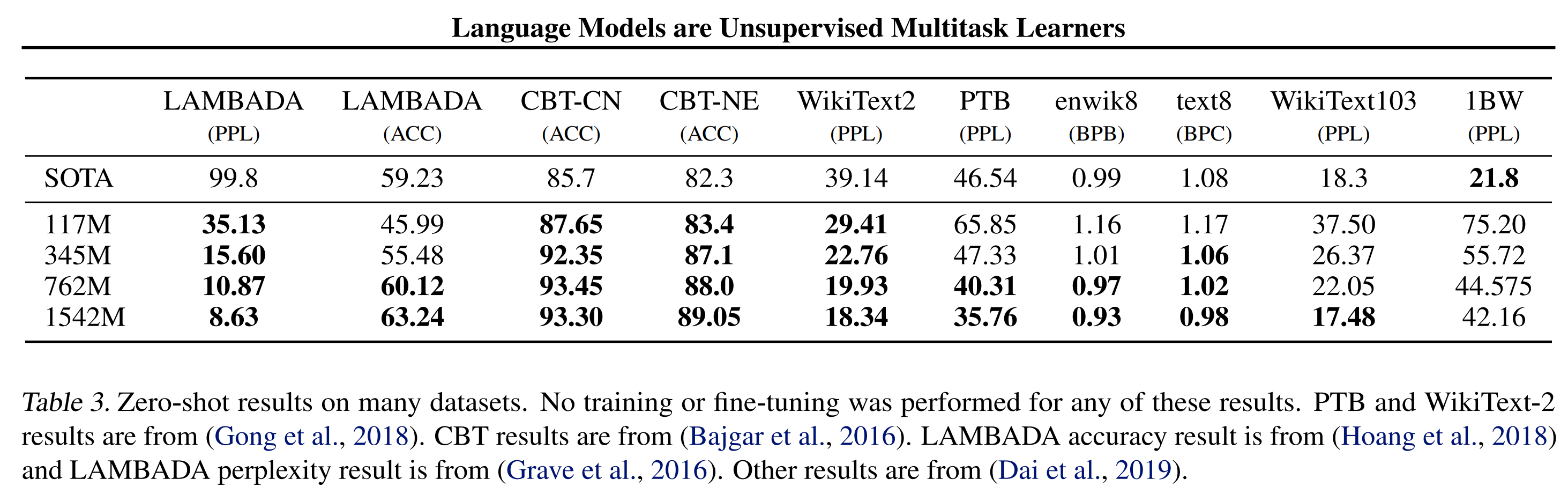
From the experiment it shows that: 1) GPT-2 with zero-shot can outperform most of the other SOTA zero-shot models on the NLP tasks (with the corresponding datasets). 2) As the number of parameters increased, GPT-2 performance also increased. The largest model almost beat all the SOTA models on these tasks.
Analysis and discussion
GPT-2 has similar performance as the supervised model on some tasks like reading comprehension and its performance is not far away from humen performance, but on the other tasks like QA it still does not work well and is no better than random, especially it's far away from human performance. When compared with the other self-supervised pre-trained models like BERT with similar number of parameters, GPT-2 does not beat their performance on the sub-tasks. That means although zero-shot learning can provide a strong pre-trained model, it may still need some fine-tuning on the specific tasks to boost its performance on the specific tasks. The quesiton is, does it need as much labelled data as the fine-tuning in each subtask or it just needs a small amount of labeled data? The following paper GPT-3 shows only a small data already (few-shot learning or even one-shot learning) helps a lot to improve the performane.
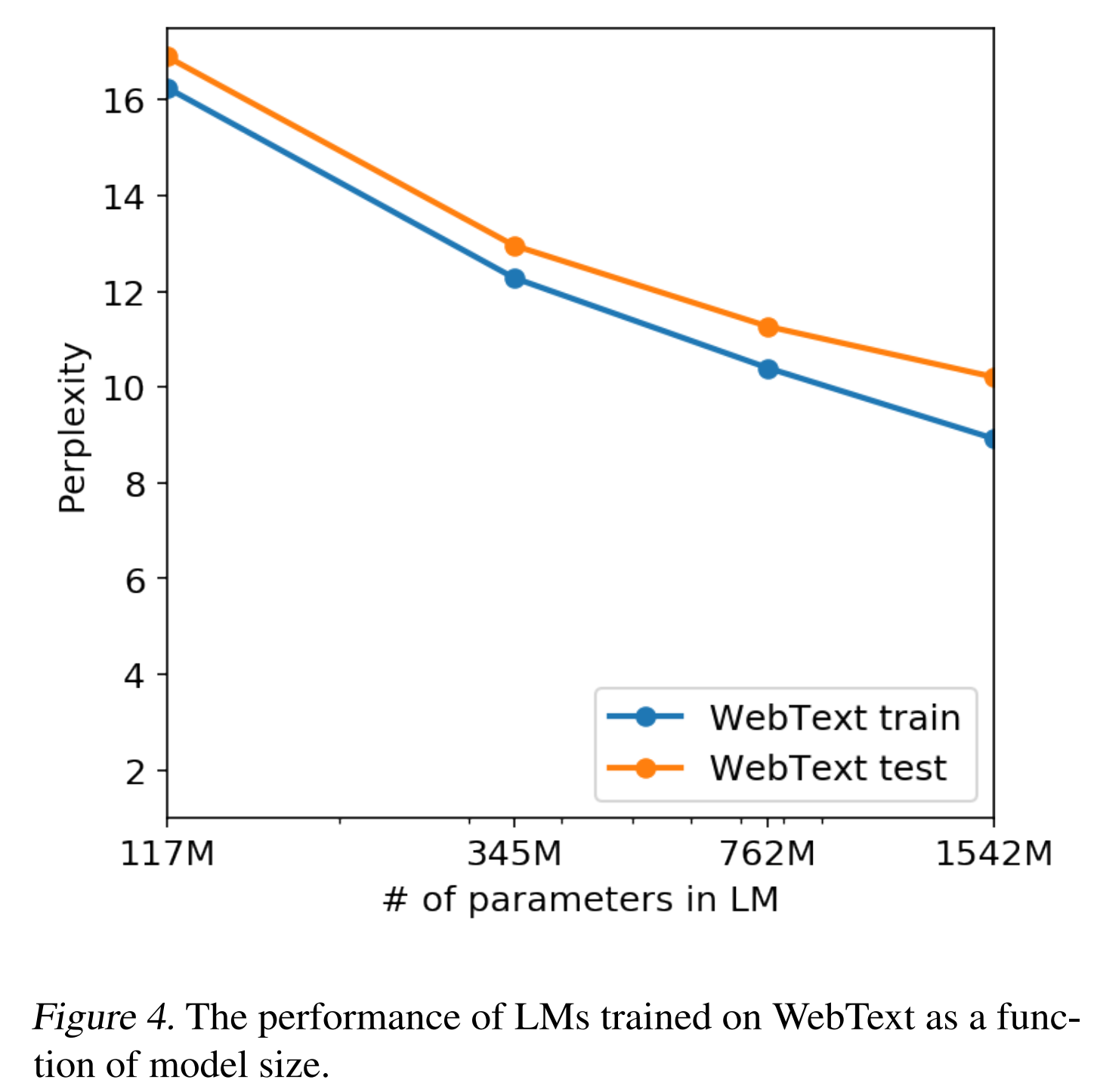
The second observaiton is that model performance still increases as the number of parameters increases (more layers and larger layer size). As the plot shown above, with the number of parameters increased in LM from 117M to 1542M, the perplexity decreased in both the training data and the test data. That also what GPT-3 will do: increase the number of model parameters and increase the training data size at the same time.
The last finding is that GPT-2 can write news articles. Although the author did not spend too much space discussing this feature, this feature is one of the main reasons why the GPT series will shine in the future - it can generate contents. We will discuss this below.
3. GPT-3
What the problem GPT-3 solve?
Models trained on the specific target task usually need task-specific dataset and task-specific fine-tuning, and thus need some labeled data. There are some limitations for this: 1) specific data for each task limits the generalizaiton of the trained model. And for many tasks it is hard to collect a large supervised training dataset; 2) the model performance may depends on the data: the potential of the trained model has a relation with the expressiveness of the model and the narrowness of the training distribution. When large model is fine-tuned on the parrow task distribution, large models do not necessarily generalize better. In other words, the fine-tuned model performing better does not mean the large pre-trained model is better. It may be just because the fine-tuning training data has overlaps witht the evaluaiton data; 3) humans can learn more efficiently without large amount of data.
To solve these concerns, GPT-3 proposed these ideas:
First: It trained a model with broad set of skills and pattern recognizaiton abiities at training time, and relies on this ability in inference time for the new tasks. Specifically, GPT-3 trains a good model with great generalizaiton capability (meta-learning) and it does not update the parameters in the large pre-trained model for the subtasks (in-context learning), but only update the output weight for that task (usually it is the last last layer) with a few data samples (few-shot learning).
It is like adding a layer for the specific task. In few-shot learning, the big model parameters will not be updated so that the generalization capability and the pattern recognizaiton capability from the pre-trained model will be retained. It only updates the paramters of the last layer for that specific task with a few samples for that specific task. For example, if it is a classificaiton task, it will have a layer for calssificaion and the paramters for that layer will be upated by the calssificaiton task data. The other paramters in the pre-trained models are frozen.
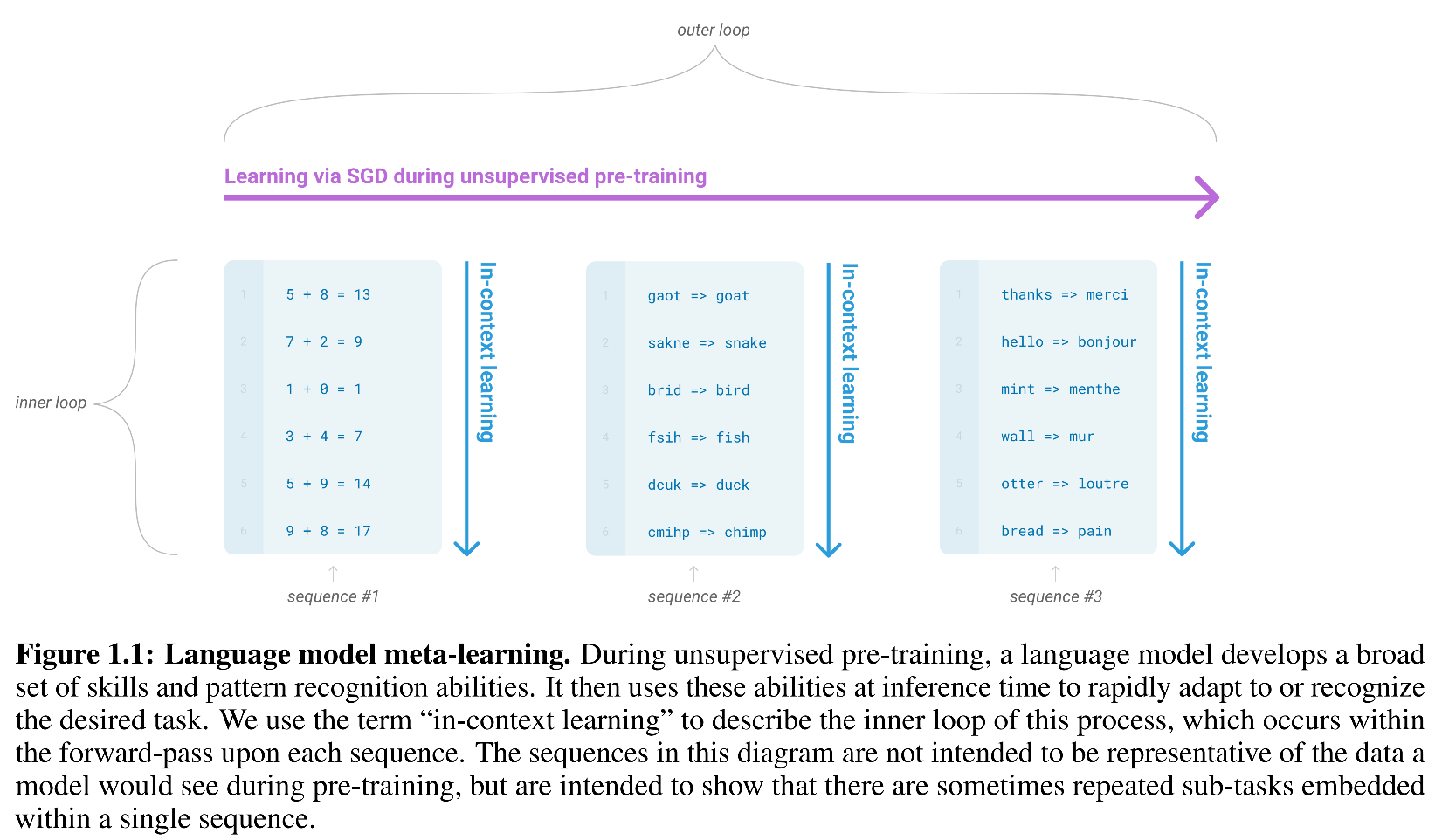
For examle in the Figure above, the big training data may have already many cases like the math sum, text work correction or translate from one language to another. In the pre-trained model, it will learn from these data to understand the task and develop a broad set of skills and pattern recognizaiton capabilities (self-supervised here with SGD). After it is learned, the big pre-trained model parameters will not be updated. It learns this capability and rapidly adapt to or recognize the task in infreence time.
Second: it trained a big model with 100 times more data and 10 times more parameters to learn. GPT-3 has 175 billion parameters and is evaluated under 3 conditions: 1) few-shot learning, which uses 10 to 100 data points to tune for the specific task. 2) one-shot learning, where only one data is used; and 3) zero-shot learning, where no additional data is used.
How does GPT-3 work (model framework)?
1. Data
GPT-2 uses reddit data from Common Crawl (CW) datasets. In GPT-3, as the model increased 10x time, the whole Common Crawl dataset was used. They also remove the duplicates of the data by comparing the two sets of the dataset. As the quality of this data is low, the authors used a model to filter out the low quality data.
The final data includes filtered Common Crawl, WebText2, Books1, Books2 and Wikipedia. As the CW data quality is not high, the sampling weights for CW is set low compared to its big size.
2. Model and Approach
The model that GPT-3 used is still transformer decoder which predicts the next token based on the previous tokens. It is similar to GPT-2 structure but using alternating dense and locally banded sparse attention patterns in the layers of transformer.
The authors explains the details of the approach they used, which includes few-shot, one-shot and zero shot, together with fine-tuning which they did not use, as shown in the Figure below.

Fine-tuning: fine-tuning is to collect thousands of data points for each task to refresh the parameters in the model. It usually has strong performance on the benchmark data, but it needs a new large dataset for each task. GPT-3 can be fine-tuned and it might be a promosing direction in the future. In fact, in the following work of InstructGPT, the authors begin to tune the parameters based on the feedback from human annotations.
Few-shot: the model will be given a few samples data of the task at the inference time, but no weights of the pre-trained model will be updated. For example, in the inference time of translation from English to French, first it will be given the task description, then some examples (10 to 100) from English to French will be given. And then a prompt will be given, the model will automatically generate the French translation based on the input in prompt. The advantage here is that only a limited number of input data is needed. The disadvantage is that the performance of few-shot learning usually is not as good as the SOTA fine-tuned model.
One-shot: it's similar to few-shot setup, but just one sample data is given after the task description. This is close to how the tasks are communicated to human. When asking human to do something, it is common to give an example of the task.
Zero-shot: there is no data after the task description. From the model using aspect, this is the easiest way to go. But it is also the most challenging setup for model to understand the task as no example is given.
One potential cave for few-shot or one-shot is: how can it remember or understand the previous input data informaion when there is new input data? For example, if 10 data points are used in few-shot for the first time, if there are another 15 data points for the second time, it seems the setup of few-shot learning cannot link the input inforation from the first 10 and the second 15 data points.
The experiment result part will be ignored. Generally it discussed GPT-3 performance on more than 10 tasks.
Limitations
Some limitations in GPT-3 are discussed and the potential improvements are also discussed for future work.
First, it is hard and expensive to train considering the large amount of parameters and the training dataset. It requires huge computing resources and time to train the model.
Second, GPT-3 has weakness in some NLP tasks like text synthesis and some comparison tasks like if two words are used in the same way in the sentence. GPT-3 has difficulty for some common sense physics quesitons to human. For example, it is hard for GPR-3 to answer "If I put cheese into the fridge, will it melt"?
GPT-3 using unidirectional approaach may have structure and algorithmic limitaion coampred to the bidirection approach. As introduced in GPT-1, this may affect GPT performance in some tasks, like fill-in-the-blank tasks, tasks that involves looking back and comparing two pieces of content, or tasks that require re-reading. Alls these tasks will be easier when the context information before and after the token is known. So expanding the bidirection function in GPT model will be a promising direction for future research (learn from BERT?).
A more fundmental limiation for GPT-3 is that it is a language model based on text data, so the pre-trained model has no idea about the other domains of experience. Like it cannot handle video data or real-world physical interactions. One promising direction is to include learning objective from humans and fine-tuned with reinforcement learning (that is what InstructGPT/ChatGPT will do), and to add additional modalities such as images and videos (that is what GPT-4 will do, it will accepct images or pdf files to descirbe or summarize the input file).
4. InstructGPT / ChatGPT
What the problem InstructGPT solve?
GPT3 limitation: First, it does not remember the previous few-shot inputs. ChatGPT can continuous rememnber what you chated with it before and based on that context information to continue the multi-round chat with you.
Second, as the model becomes bigger and bigger, the output from GPT-3 sometimes is hard to control. For example, if you ask about What is Gaussian Process, it may generate some low quality text to you. Or sometimes model may generate some harmful informaiton like biased, racist or gender discriminative text.
Third, language model use self-supervised method to pre-train a big generalization model. As there is no labeled data in self-supervised model, if you want the model to answer some question like "what is Gaussian Process", the training data should have included this information so that the model can learn it. So, in order to let the model have enough generalizaiton capability, the training data text should be big enough.
The reasons for these unintended behaviors are mainly because the language models's objective is trying to predict the next token (that is that GPT-1/2/3 did, using transformer decoder to predict the next word given the previous tokens), which is different from the objective to follow the user's instruction helpfully and safely. To overcome these limitations, InstructGPT used the labeled data to fine-tune GPT-3 model to align the language model with reinforcement learning from human feedback (RLHF) to fine-tune GPT-3 to follow the human written instructions and use human preferences as the reward signal to fine-tune the model.
How does InstructGPT work (model setup)?
InstructGPT include fine-tune GPT-3 with labeled data to train a supervised fine-tune(SFT model) to generate outputs, a reward model (RM) to compare the diffent answers generated from SFT, and reinforcement learning on the reward model to guide the SFT generation.
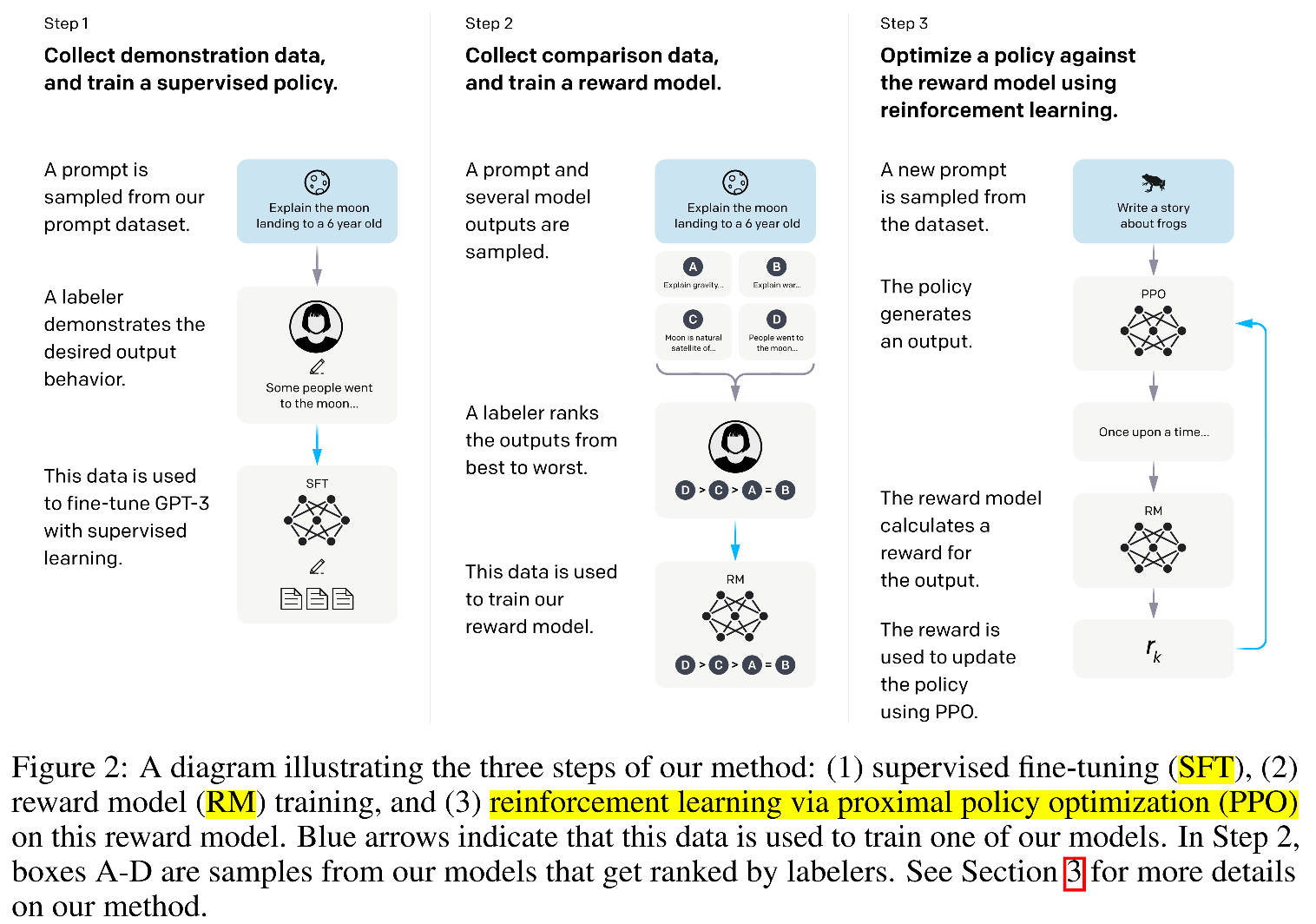
Step 1. Sample a prompt from the prompt dataset, and then human (or the model) write the answer for that sampled promot. After the promot and the answer is ready, it will be send to fine-tune GPT-3 with supervised learning (SFT). The challenge here is that it is expensive to get human prepare the answers for the prompts. With this model, it can learn how to generate the answers based from the SFT.
Step 2. When a promot is give, it first use GPT-3 to generagte several answers for the given promot. For example, if 4 answers are generated, they will be marked as A, B, C, D. Then human will just need to rank the answers (e.g., A>B>C=D). In this way, human does not need to write the answers but only just rank the model generated answers. With this comparison data, InstructGPT trains a reward model to compare the 4 <prompt, answer> pairs so that the ranking relation can be larned in the reward model (RM). With this model, it can be used to compare the generated answers and calcualte the reward.
Step 3. Now they can use the RM to guide the SFT model to generate better results to achieve higher RM reward. InstructGPT use the output of the RM as a scalar reward and fine-tune the supervised policy to optimize this reward. The trained model is called InstructGPT.
Accordingly, there are 3 datasets: 1) SFT dataset (13k prompts) to train the SFT model; 2) RM dataset (33k prompts) with labeler rankings of model output to train the RM model; and 3) PPO dataset (31k prompts) without human labels as input for RLHF fine-tuning.
More details about the models
SFT: it is a supervised model by fine-tuning GPT-3 on the SFT data in which eash data point is a promot and the answers by the labelers. AS there are only 13k data, the model overfits after 1 epoch. However, training for more epochs will help in the RM score model.
RM: first, it replaces the last layer of SFT model (which is softmax layer) by a linear layer to output a scalar reward. So for each input <prompt, answer> to the modified SFT model, it will output a scalar value (reward). If one prompt has \(K\) answers, to compare them pairwisely, there will be \(C(K,2)\) combinations. For two answers \(y_w\) and \(y_l\), if \(y_w\) is better than \(y_l\), the purpose is to discriminate the two answers as much as possible, so the loss function is a logit loss of the delta of the two reward \((r(x, y_w) - r(x, y_l))\). The authors mentions that they used the pairwise answers comparision (where there are \(C(K, 2)\) pairs of data) rather than to select the best answer will help to avoid overfiting.
RL: The purpose of RL is to learn a better GPT-3 model \(\pi_{\phi}^{RL}\) to generate the answers. The objective function is designed to guide the model towards generating responses that adhere to the given instructions or constraints provided by users.
It has 3 terms. The meaning of each term is:
The first term \(E_{(x, y) \sim D_{\pi_{\phi}^{RL}}}[r_{\theta}(x, y)]\) in the objective funciton says that for the new model generated answer \(y\), it tries to maximize the expectation of the reward model. \(\pi_{\phi}^{SFT}\) is the SFT model from the labeler written data. \(\pi_{\phi}^{RL}\) is the model learned from RL with the generated data, where \(\phi\) is the parameter. It is initialized as the SFT model. \((x, y) \sim \pi_{\phi}^{RL}\) means putting prompt \(x\) into the model \(\pi_{\phi}^{RL}\) to generate answer \(y\), and then put the generated pair \((x,y)\) into the trained RM to calculate reward, and the final target is to maximize this reward. In this way the new model \(\pi_{\phi}^{RL}\) will be close to the best model from the labeler.
The second term in the objective is the expection of \(\beta \log (\pi_{\phi}^{RL}(y|x) / \pi_{\phi}^{SFT}(y|x))\), which is KL divergence. The purpose of adding this term is that: after many interations, \(\pi_{\phi}^{RL}\) and \(\pi_{\phi}^{SFT}\) could be more and more different. However, the reward model \(r_{\theta}\) is trained from the first SFT and the corresponding \(y\). Now if the new model and the original SFT model are different, then the reward model will not work any more to evaluate. Adding this penalized term is to make sure the RM model can still be effective to evaluate the new model \(\pi_{\phi}^{RL}\). This is what "PPO" means.
The third term \(\gamma E_{x\sim D_{pretrain}}[\log(\pi_{\phi}^{RL}(x))]\). That is, for the pretrained data of GPT-3, it calcualtes the loss and adds it to the objective. If \(\gamma = 0\), it is called PPO-ptx model.
What ChatGPT did? ChatGPT use the same method as InstructGPT but with slight difference in the data collection setup. ChatGPT use multi-round dialogue data and fine-tuned from the model in GPT-3.5.
5. GPT-4
OpenAI GPT-4 Technical Report
GPT-4 is a transformer-style model pretrained to predict next token in a document. GPT-4 is a large multimodela model that can accept both image and text input prompts and output text. It was fine-tuned with RLHF (See above in InstructGPT) to improve the model's broader general knowledge and advanced reasoning capabilities
GPT-4 training was stable. As the model is very big, it may fail during training process because of many reasons: loss does not converge, gradients exploding, hardware issues like machine failed, network connection broken. All these will bring lots of engineering challenge for model training.
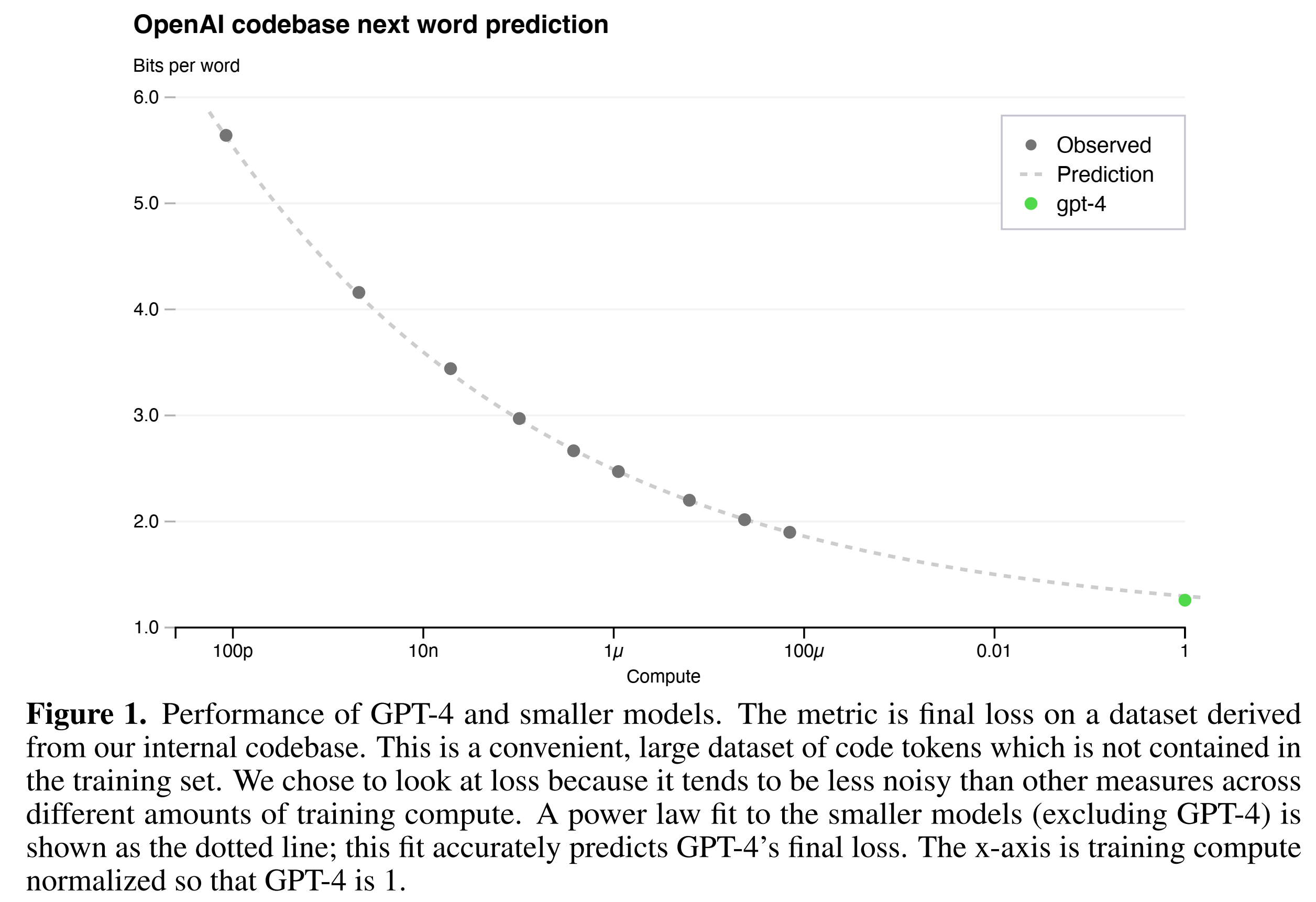
Training performance can be predicted ahead of time. OpenAI developed the infrastructure and optimization that have very predictable behavior across multiple scales such that they can predict the final loss of the very large model GPT-4 by extrapolating from models trained with the same methodology but with \(10^{-4}\)x less compute.
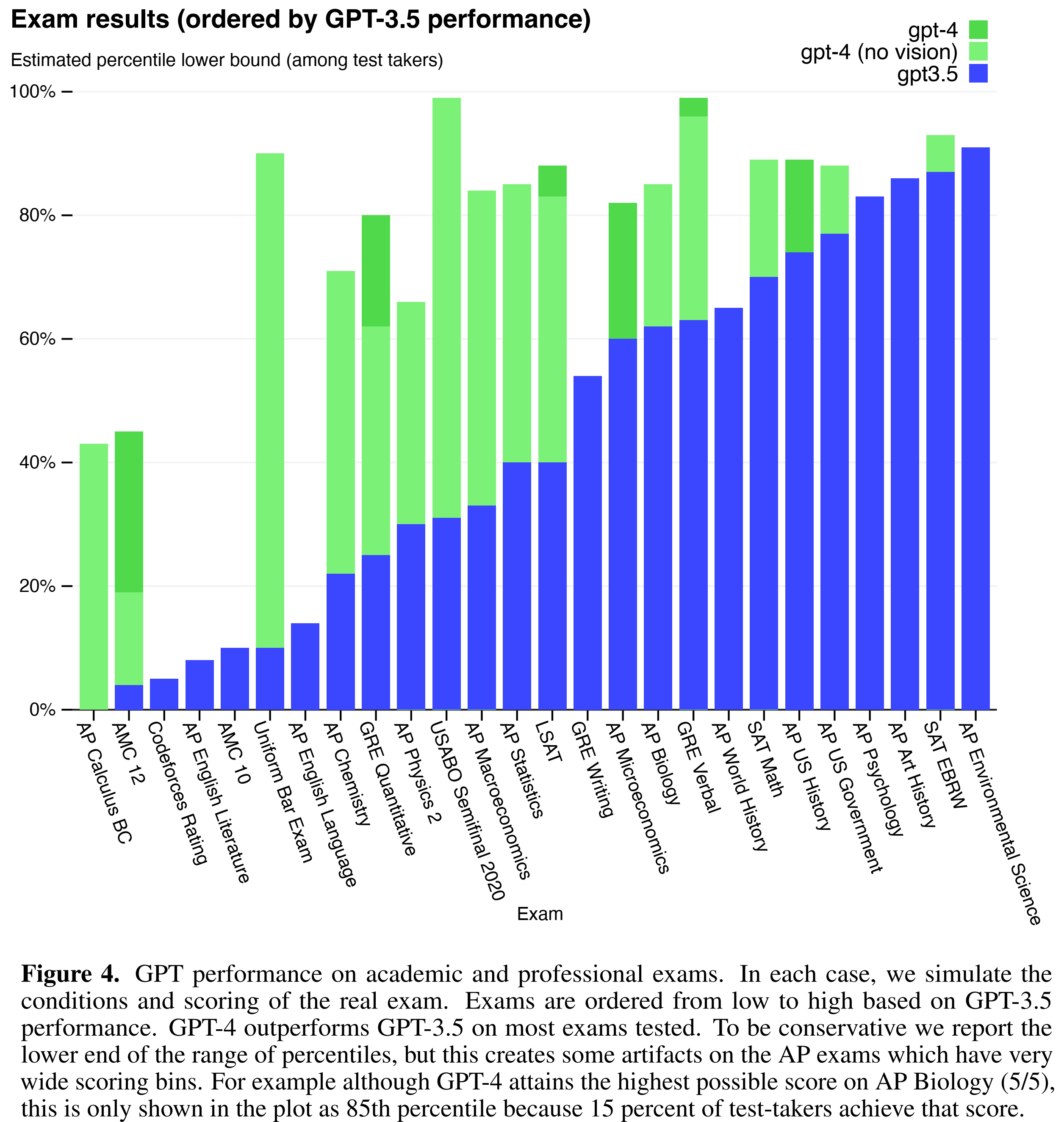
Capability. GPT-4 improves significantly compared to GPT-3.5. It exhibits human level performance on the majority the professional and academic exams. The model’s capabilities on exams appear to stem primarily from the pre-training process and are not significantly affected by RLHF.
Steerability. GPT-4 allow users to use "system" message to customize the experience within bounds. Generally "system" message tells GPT-4 to follow the users's instruction to provide additional information, instructions, or context during the conversation.
Overall, the tech report did not touch too much details about the model, the training data and how OpenAI trained the complicated model.